
How we built and manage an AI teammate to fix bugs
12 May 2026
We're bullish on humans. What a weird sentence to write. There's a lot of chatter right now about whether AI is going to take all of our jobs. Are we heading for some dystopian future of single person companies managing fleets of autonomous agents doing work humans used to do? We don't think so. But work is going to change. More specifically, what we work on is going to change.
A couple things I read and watched (around 49:30) last week make a similar reference to accountants. Back in the not so distant past, accountants used to have to compute everything by hand. And then along came these things called computers. They were going to automate all the computing and replace accountants. But what we've actually seen in the 40 years since is 4x growth in accountants above and beyond population growth. Instead of replacing accountants, computers meant the nature of the work could shift. Suddenly, more became possible.
We think AI will follow similar storylines. When was the last time you spoke to a friend who wasn't completely swamped with their work? The reality in most roles is we just can't keep up. There's a laundry list of things we know we could do better that we never get to. If only we had the time. If AI allows us to hand off work that used to require a human, how many of those things become newly possible?
We'll go deeper on this shifting nature of work in other posts. It's clear that the scale of the impact will be asymmetrically applied across different roles and industries. What is unclear is how those roles may shape shift and evolve. For now, I wanted to share one example of how this shift in the nature of work is already playing out in how we build HappyHQ.
Bugs
Bugs are a part of every engineering team's workflow.
A bug gets reported. A ticket gets opened. Someone on the team triages it, assigns a priority, assigns an engineer. The engineer tries to reproduce it, figures out the fix, ships it. If all goes well, everyone moves on.
This works, but it's hard to scale. An engineer is hands-on for all of it. Your ability to get through your bug backlog is basically a function of how many bugs there are and how many engineers you have.
Now with coding assistants, an engineer asks an assistant to follow their directions. If all goes well, the assistant helps them understand the bug faster and hopefully fix it faster. I think of this as the 2x gain. But engineers are still the bottleneck. We're still touching every bug, even if we're able to do it faster.
If you're thinking background agents could help us go further here, we'll come back to why we haven't reached for them yet.
Designing an AI teammate focused on bugs
Rather than having to work on each bug ticket directly, we want as many of them as possible to be done by Ralphie — what we call our coding assistant (named after Geoff Huntley's Ralph Wiggum loop, worth a read!).
We spent time thinking about how we'd want bugs handled if we could design the process from scratch. What should happen when a bug comes in? How do we choose which bugs to work on? What does great work look like? Are there stages to this work? What things should be considered? What does done look like?
We wrote all of that thinking down. Then we asked Ralphie to do the work we used to do. While it might seem like we've just replaced ourselves, we haven't. Ralphie is doing the work, solving the bugs the way we defined. Now our job is to watch that work get done. To see how Ralphie behaves. To observe what's working and what's not.
Ralphie is going to get things wrong. Maybe it's because our thinking had a gap. Maybe it's the first time we've seen a bug like this. Maybe it's straight up hallucination. It doesn't really matter what the reason is, we should expect Ralphie to misbehave in certain scenarios. Our job is to identify those scenarios and think through ways to help Ralphie make fewer mistakes.
This is also why we haven't reached for background agents yet. Background agents optimize for autonomy — Ralphie goes off and does the work somewhere else. At this stage, we're optimizing for learning. The whole iteration loop depends on watching Ralphie misbehave and updating the way Ralphie works in response. You can't iterate on what you can't see.
Then comes the fun part. As Ralphie starts to take on more and more bugs, and we address the low hanging fruit, we can start to think about how to improve our approach to bugs in ways we never had time for before. What would better look like? Some of that will be improvements to the bug flow itself. Other parts of that work may be spent trying to reduce the number of bugs in the first place.
The end result is an iterative loop where we are constantly improving the quality of our work.
How our AI teammate handles bugs
Let's dig into the mechanics a bit. HappyHQ is open source, so all of this is publicly available. You can go look at the actual files if you want on our Github.
The basic building blocks are pretty simple. We use GitHub issues to track bugs and labels to manage their status. Then we have two prompts — one for the triage behavior and one for the fix behavior. These tell Ralphie what to do on each turn of the loop. Both prompts load a bugs-rubric.md that describes how we want Ralphie to approach the work. The prompts tell Ralphie what to do; the rubric tells Ralphie how to make decisions.
Thinking in stages: triage and fix
Most of our flows rely on more than one stage. It's tempting to point Ralphie at a task and just say "fix it," but in practice you get better results by being intentional about pre-work and post-work. For bugs, we triage issues before Ralphie is able to fix an issue.
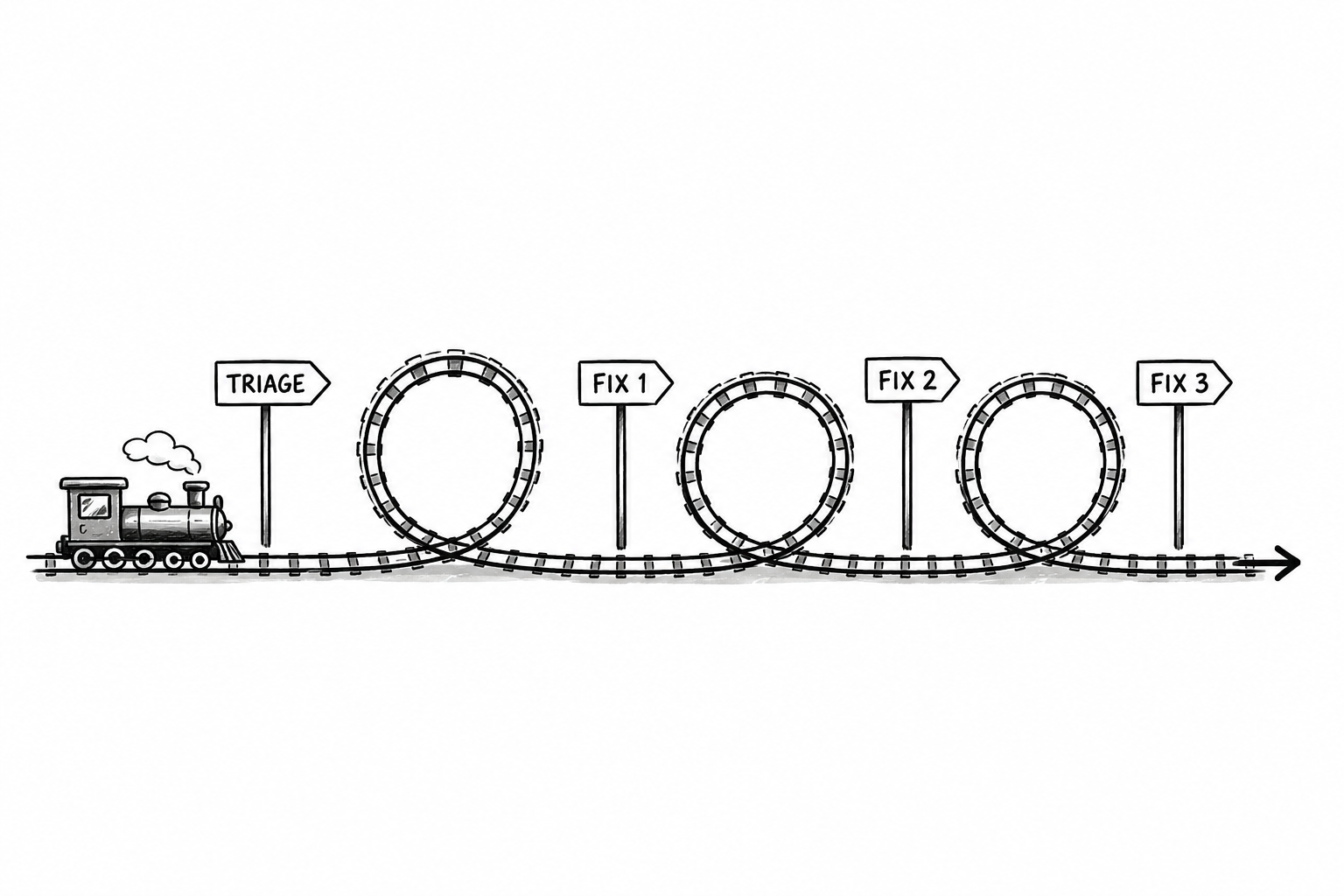
Each stage runs in a loop where every turn does exactly one thing. The loop is either triaging issues or fixing one issue. This keeps things focused and avoids the pitfalls of giving an LLM too much to do at once. More on that in a future post.
Everything Ralphie does leaves a trail. It makes the work visible to the humans checking in. And it makes sure the next run of the loop doesn't try to redo work that's already been handled.
| Label | Why |
|---|---|
bug |
In the queue. Ralphie can pick this up. |
ralphie:fixed-in-pr |
Ralphie shipped a PR. Done. |
ralphie:split-into-children |
Right fix was too big to review as one PR. Broken into smaller issues. |
ralphie:skip-needs-rescope |
The report was asking for the wrong fix. Ralphie filed a corrected version and linked back. |
ralphie:skip-* |
Something blocked Ralphie from working this one — touches ee/, needs a decision, can't be reproduced, etc. A comment explains what would unblock it. |
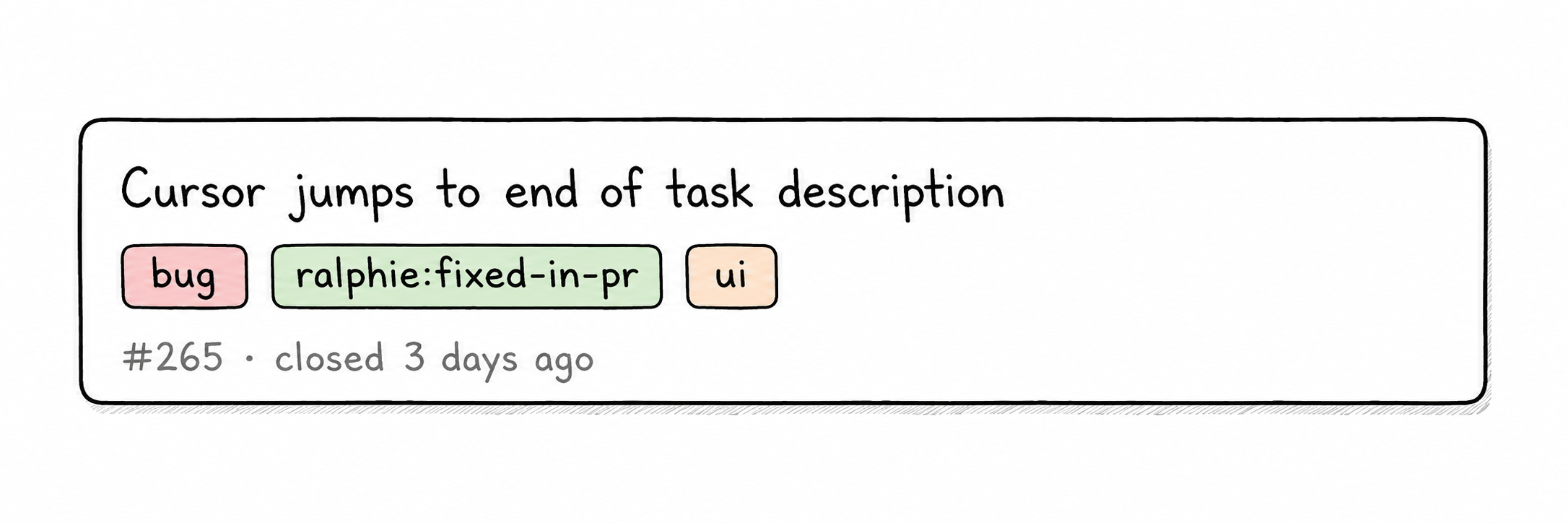
Triaging the backlog
We start with triage. Ralphie looks at all open bug issues in Github that have the bug label but no ralphie: label. That's the backlog Ralphie hasn't touched yet.
Then it goes issue by issue. It's a chance to add detail, reframe, skip, or punt. Anything that gets skipped is effectively a flag that a human is needed.
Here is what we tell Ralphie when deciding whether to skip:
Bail before engaging when the issue isn't workable:
- Out of scope — touches our paid tier, needs a schema migration, env var, or CI change.
- Not enough information — no way to reproduce, reporter unreachable.
- Needs a human decision — unresolved questions for the maintainer.
- Too big for one reviewable PR.
- Verification fails after a couple of tries.
The full rubric has the exact wording.
Fixing a bug
Once triage finishes, we start the fix stage. Each turn picks up one bug that made it through triage.
We tried to make Ralphie's job simple by asking one question:
Am I fixing the right thing, the right way?
A session walks through five steps on the way to answering it:
- Reproduce — get the bug to happen locally.
- Understand — read the code and form an opinion about what's actually broken.
- Fix — implement the change.
- Verify and validate — automated checks prove the code is healthy; actually using the change proves the bug is fixed.
- Decide — based on the diff in hand, the session ends in one of four outcomes: ship, split, rescope, or skip.
The rubric defines what each outcome means and what good looks like. It includes a set of Hard Constraints Ralphie can never violate, like:
- One outcome per session. After labeling, opening a PR, splitting into children, or filing a rephrased child issue, exit.
And a set of Principles that shape every decision, like:
**A fix isn't just the diff.** Leave the surrounding code consistent with the change. If the fix changes documented behavior, update the spec in the same PR. If you notice a pattern across recent issues, surface it for the maintainer. If you skip, leave a rationale specific enough that a human can act on it without re-investigating.
There's no perfect structure to a rubric like this. The goal isn't perfection — it's starting with something workable and iterating to improve Ralphie's behavior over time.
Early iterations with our AI teammate
Running the loop is the easy part. You run ./bugs.sh and Ralphie works through the steps above. The important part is what happens next — staying close to the work and watching how Ralphie behaves, and, more importantly, how Ralphie misbehaves.
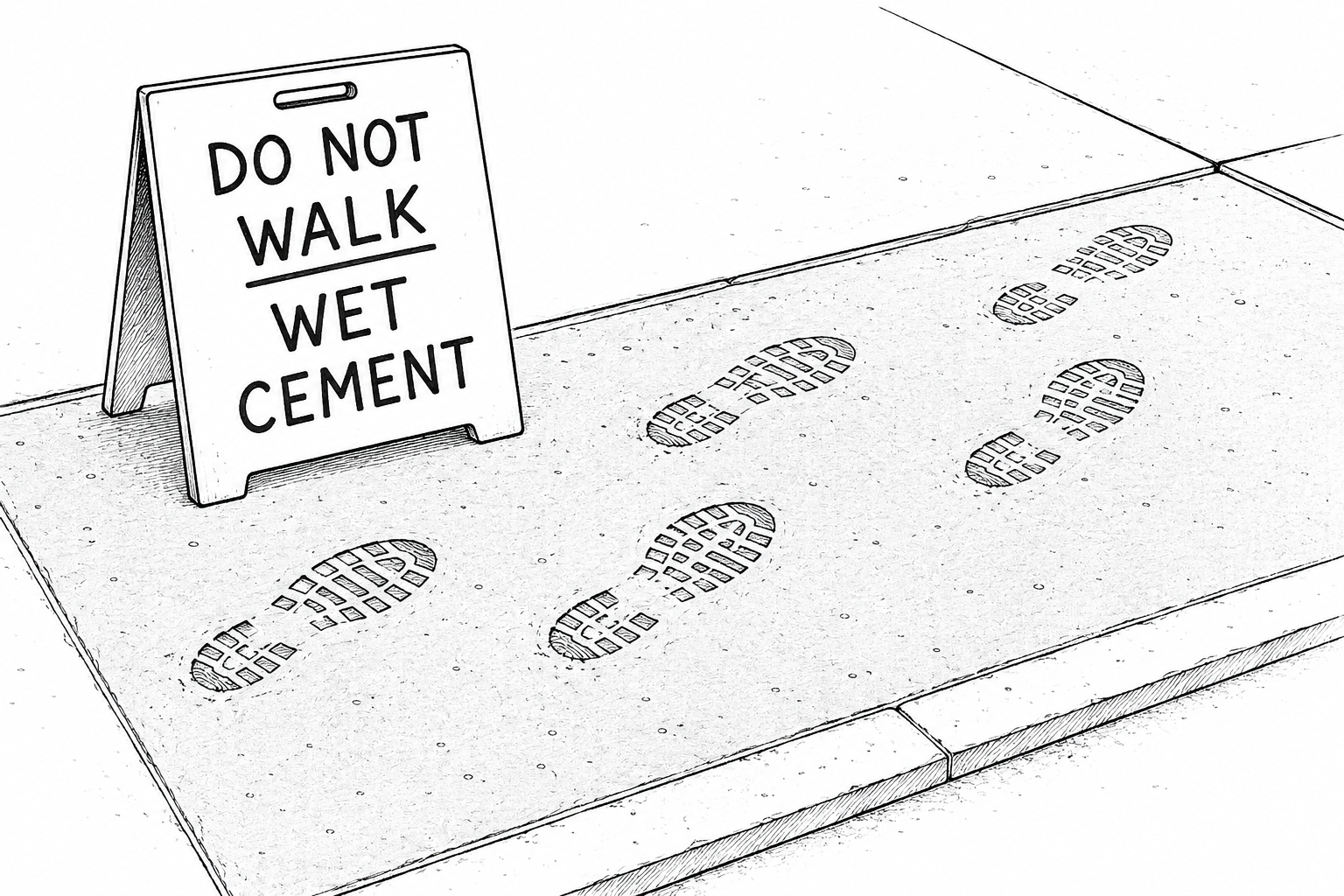
Early on, Ralphie would open a PR saying a bug was fixed. Tests pass. Code looks valid. Great. Then we'd go and test it ourselves and the bug was still there. Ralphie had written working code, but it hadn't actually checked whether the user-visible problem was solved.
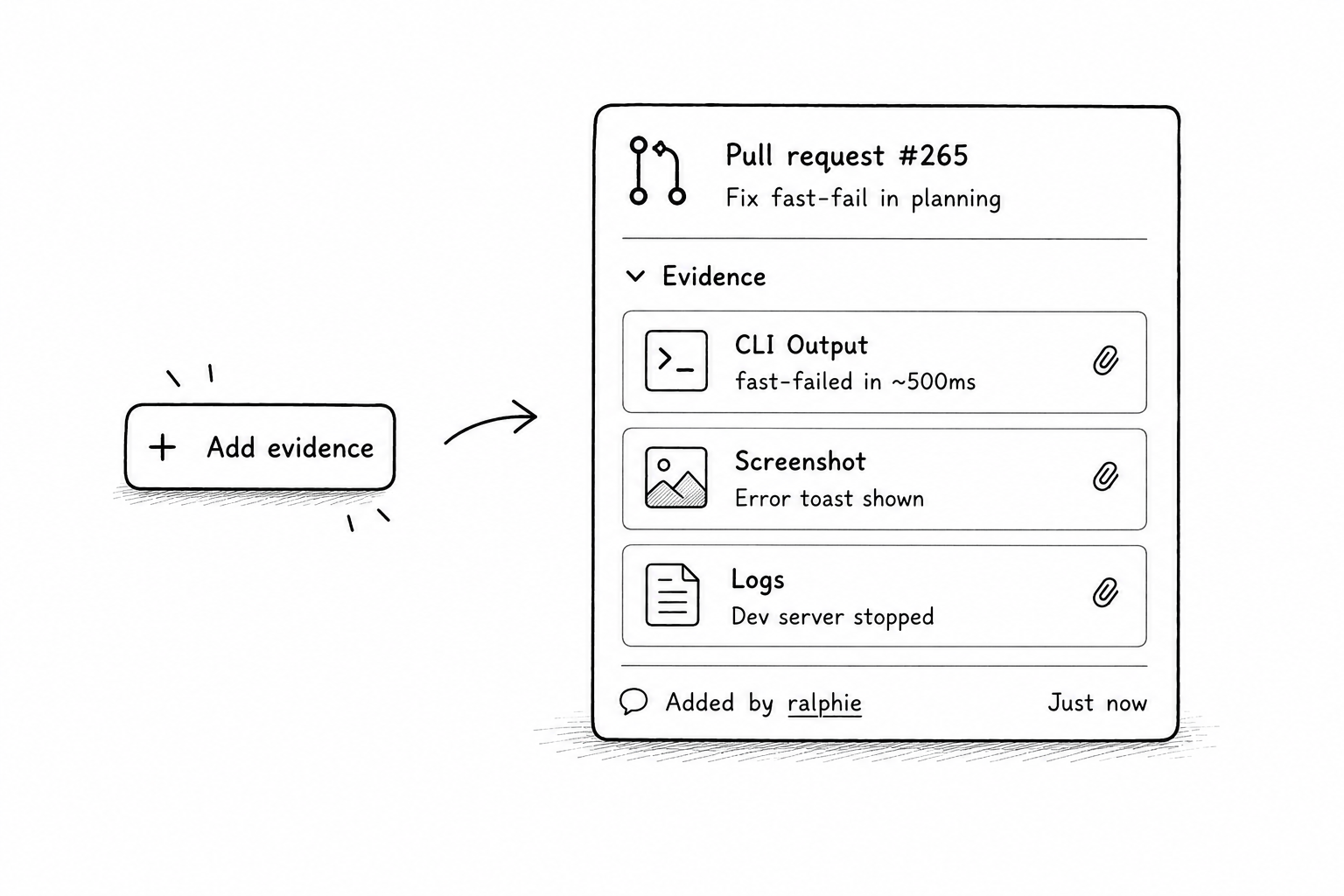
So we added a step to the fix loop. Before opening a PR, Ralphie now has to exercise the fix — boot the dev server, hit the affected surface, and share the evidence in the PR. Screenshots, API responses, whatever proves it actually works. You can see what this looks like in this PR (look for the verification section).
There are lots of these stories and we expect a lot more as we continue working with this flow. This is an approach built around a principle of continuous improvement. Ralphie does the work, you manage the work and focus on ways to make it better.
What's next
We're taking this same approach across the rest of our engineering work. Future posts will explore how we're doing a similar thing for tech debt, dependencies, and QA. Things start to get even more interesting when these flows hand off to each other. When the outputs of the bug flow get picked up by the QA flow.
If this way of thinking resonates, it's exactly what we're building with HappyHQ. But for everyday folks doing everyday work. More on that another time.